初見でひっかかったPerlのmapとハッシュと配列
こんにちは。
Perl歴2ヶ月ほどとなりましたが、Perlをはじめて1ヶ月の頃に躓いた話をします。
これから話す内容は、先日Perl未経験の新卒エンジニア1名に解かせてみたところ、引っかかったので、初心者*1は引っかかりやすいポイントだと思います。
同じ引っかかりをするかな(したら共感があるな)、という気持ちを込めて、本題までゆっくりと話していきます。
やっていくぞ
まずは、こちらをご覧ください。
use strict; use warnings; sub get_english_to_japanese { return +{ apple => 'りんご', phone => '電話', }; }
はじめにPerlが知らない人向けに言っておくと、strictとwarningsは、滅茶苦茶なソースコードの誕生を避けるために宣言すべきなものです。
これを宣言しないと、未定義の変数を突然利用できたりします。
get_english_to_japaneseは、英語と日本語の組のハッシュのリファレンスを取得するサブルーチン(関数)です。
( + は、ハッシュリファレンスであることを明示するためにつけている記号です)
大体他の言語をやっている人なら、「RubyのHashやPythonのDictみたいな感じね」という感じで雰囲気掴んでもらえるかと思います。
リファレンス とは、という話はここでは割愛します。
わからなくても問題ないですが、気になる人向けにperldoc.jpを置いておきます。
perldoc.jp
はてなキーワードもあるぞ。
リファレンスとは 一般の人気・最新記事を集めました - はてな
さて、実行すると、こんな感じで表示されます。
use DDP; my $hashRef = &get_english_to_japanese; # &は無くても良い。サブルーチンだと分かりやすいかなと思って書いた p $hashRef;
DDPを使うと、簡単に中身を見ることができて便利です。
% perl sample.pl
{
apple "りんご",
phone "電話"
}
printだと結果はこんな感じになります。
print $hashRef; > HASH(0x15580aa68)
リファレンス(ハッシュ全体を参照するスカラ)になっていて、そのままでは読めませんね。
後置デリファレンスを使ってデリファレンスします。
print $hashRef->%*; > appleりんごphone電話
DDPを使った結果と比べると読みにくいですね。
sportsを足してみる
さて、ここでget_english_to_japaneseに他のペアも追加したいと思いました。
スポーツ系の単語を追加したいと思ったので、スポーツ系の単語をまとめたサブルーチン(sports)を作成し、get_english_to_japaneseからsportsを呼ぶことにしました。
use strict; use warnings; sub sports { return [ { english => 'soccer', japanese => 'サッカー', }, { english => 'baseball', japanese => '野球', }, ]; } sub get_english_to_japanese { my $sports = sports; return +{ apple => 'りんご', phone => '電話', # ハッシュの配列を作成 ( soccer => 'サッカー', baseball => '野球' ) map { $_->{english} => $_->{japanese} } $sports->@*, }; }
実行すると、このような結果が得られます。
% perl sample.pl
{
apple "りんご",
baseball "野球",
phone "電話",
soccer "サッカー"
}
やった!実装できましたね。
colorsを足してみる
この調子で、色のペアも追加していきます!
sub colors { return [ { english => 'red', japanese => '赤' }, { english => 'yellow', japanese => '黄', }, ]; }
sub get_english_to_japanese { my $sports = sports; my $colors = colors; return +{ apple => 'りんご', phone => '電話', map { $_->{english} => $_->{japanese} } $sports->@*, map { $_->{english} => $_->{japanese} } $colors->@*, }; }
さっきと同じノリで、sportsの後ろにcolorsを足して、実行します。
ERROR
% perl sample.pl
Can't use string ("red") as a HASH ref while "strict refs" in use at sample.pl line 37.おや、怒られてしまいました(´・_・`)
37行目は`map { $_->{english} => $_->{japanese} } $sports->@*,`の行ですね。
mapが展開されて、↓のような結果で実行されると思ったのですが、何が問題なのでしょうか?
どうすれば意図した出力結果を得られるのでしょうか。
return +{ apple => 'りんご', phone => '電話', ( soccer => 'サッカー', baseball => '野球' ), ( red => '赤', yellow => '黄' ), };
ところで、「おや?ハッシュの中に配列が入っている?」と違和感を感じている人向けに説明をすると、Perlでは、配列の中の配列は展開・連結される仕様となっています。
配列の中の配列?はい、PerlのHashは、文字列がキーになった配列です。
また、次の二つは同じです。
(さらに、1の書き方の場合は、キーの文字列をクォーテーションで囲まなくても大丈夫です)
1. ( apple => 'りんご', banana => 'ばなな' ) 2. ( 'apple', 'りんご', 'banana', 'ばなな' )
ハッシュとして扱えばハッシュ、配列として扱えば配列になります。
{
apple "りんご",
banana "ばなな"
}
[
[0] "apple",
[1] "りんご",
[2] "banana",
[3] "ばなな"
]
ちなみに、 => のことをfat commmaと呼びます。
「Perl fat comma」で調べると、有益な記事が多く出てきます。
このあたりについては、O'Reilly Japan - 初めてのPerl 第7版で、2の書き方→1の書き方の順番で丁寧に説明しています。
Deparse してみる
では、実際どうなのか?そのことを調べるために、Deparseを使います。
% perl -MO=Deparse sample.pl
sub sports {
use warnings;
use strict;
return [{'english', 'soccer', 'japanese', "サッカー"}, {'english', 'baseball', 'japanese', "野球"}];
}
sub colors {
use warnings;
use strict;
return [{'english', 'red', 'japanese', "赤"}, {'english', 'yellow', 'japanese', "黄"}];
}
sub get_english_to_japanese {
use warnings;
use strict;
my $sports = sports();
my $colors = colors();
return {'apple', "りんご", 'phone', "電話", map({$_->{'english'}, $_->{'japanese'};} @$sports, map({$_->{'english'}, $_->{'japanese'};} @$colors))};
}
Deparseしたことで原因がわかりましたね。
つまり、下記のように、mapの解釈が意図と違って解釈されていた、というわけなのです。
一つ目のmapが取る配列が、二つ目のmapの結果の配列と結合しているんですね。
return +{ apple => 'りんご', phone => '電話', map { $_->{english} => $_->{japanese} } ( $sports->@*, map { $_->{english} => $_->{japanese} } $colors->@* ), };
mapのところを一部展開してみると、こんな感じですね。どうみてもおかしいね。
map { $_->{english} => $_->{japanese} } ( ( { english => 'soccer', japanese => 'サッカー' }, { english => 'baseball', japanese => '野球', }, ), ( red => '赤', yellow => '黄' ) ),
というわけで、解決策は、「(一番最後以外の)mapに明示的に括弧をつける」でした。
ただ、次にまたmapが増えるかもしれないことを考えると、統一感を出して全てに括弧をつけるようにすることが良いと思います。
括弧の付け方は二通りあります。
( map { $_->{english} => $_->{japanese} } $sports->@* ), map ( { $_->{english} => $_->{japanese} } $colors->@* ),
この状態でDeparseすると、括弧の位置が意図した通りになっています。
map({$_->{'english'}, $_->{'japanese'};} @$sports), map({$_->{'english'}, $_->{'japanese'};} @$colors)
おわり
というわけなので、mapとハッシュと配列を一緒に扱うときは気をつけましょう。
そして、DPPとか、Deparseとか、これらは困った時に役立ちますね。
はやくこういったツールを使いこなせるようになりたいと思います。
ところで、はてなキーワードにはPerl関係のキーワードが豊富そうで、書いていて面白いですね。
読んでいてわからなかったらキーワードに飛んでくれ!ってできそうなところが良い。
![]() id:CNaanのこれからのご活躍にご期待ください( ˘ω˘ )
id:CNaanのこれからのご活躍にご期待ください( ˘ω˘ )
では。
Rubyでも同じようなことできるのかなって思って途中までやったけどPerlと全然違うコードになってきたのでやめた (¦3ꇤ[▓▓]
*1:特に既存のコードの雰囲気を真似て書こうとする人とか
VR空間で歩いた軌跡のログをとって見てみる
はじめに
この記事は、SLP KBIT Advent Calendar 2021の10日目の記事です。
他の部員の記事は以下からご覧ください!
adventar.org
今回は、VRでの動きのログをとって、眺めることができたら面白そうだな~~と思ったので、それをやっていきます。
GitHubのURLは → Amakuchisan/WalkingHistory です。
簡単に見ていくために、今回は下のような空間を用意しました。
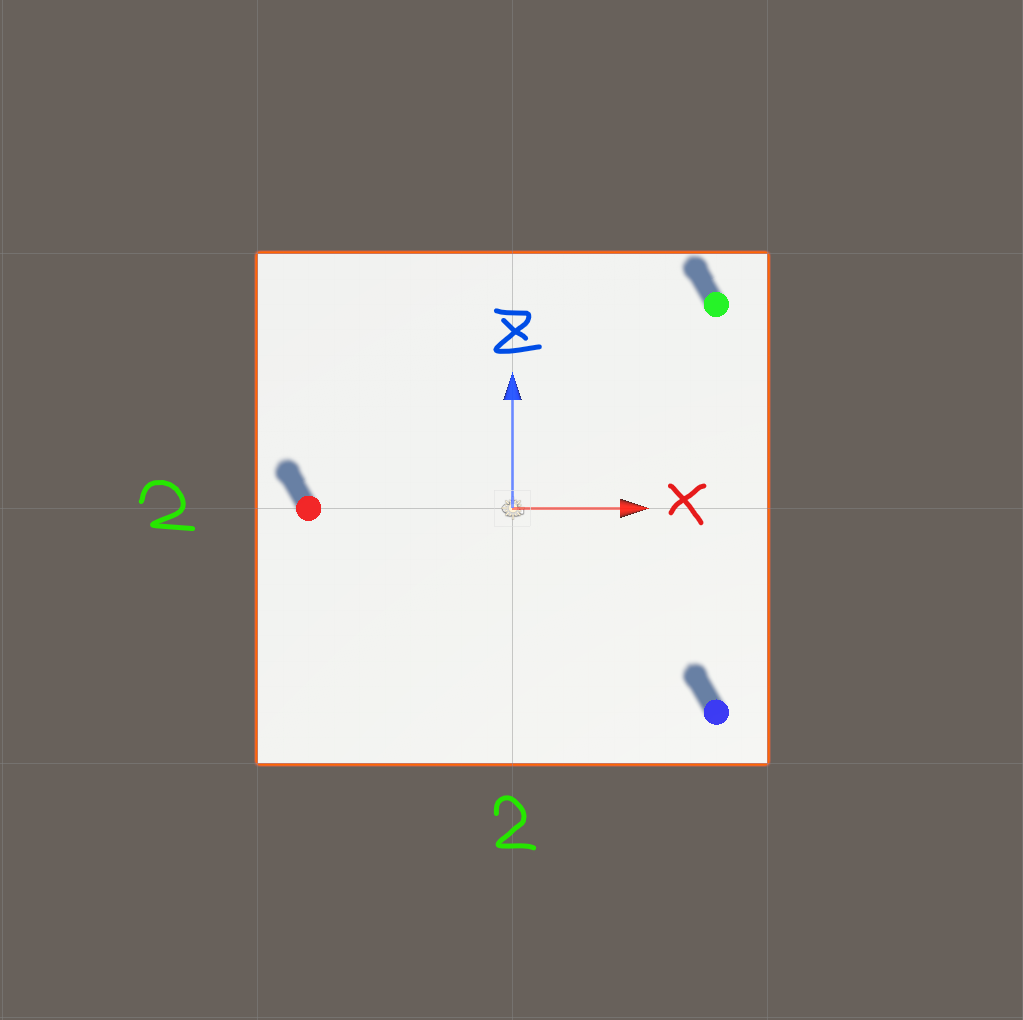
ヘッドセットはOculus Quest2を使い、プレイヤーの移動などは、Oculus Integrationのアセットを使用しています。
また、Quest2を使っていますが、今回はOculus Linkを使って、PCアプリケーションとして作成しています。
VR空間での移動を実装することはとても簡単で、Oculus Integrationのアセットからコピー&ペーストするだけで実装できます。
Assets/Oculus/VR/PrefabsのOVRPlayerControllerをシーンに配置し、Assets/Oculus/SampleFramework/Usage/にあるCustom Handsのシーンから、設定済みのCustomHandLeft、CustomHandRightの二つを拝借し、それぞれをOVRPlayerControllerのLeftおよびRightHandAnchorに貼り付けるだけです。
初期設定などは、よくこちらを参考にしています。
ファイルの生成
ファイルの生成場所
ファイルの保存場所には、実行中の一時的なデータの保存場所や、永続的なデータの保存場所など、いくつか存在します。
今回取りたいログは、永続的に保存したいので、Application-persistentDataPath - Unity スクリプトリファレンスを使います。
Application.persistentDataPathは、永続的なデータディレクトリのパスを返します。
例えば、私のWindowsの環境の場合は、 C:\Users\{ユーザ名}\AppData\LocalLow\DefaultCompany\プロジェクト名 を指します。
データの取得
今回は、2秒に1回のペースで現在の時間、位置情報と正面の向きを取得するようにしました。
(正面の向きについては、一応取得はしましたが、今回ほとんど役立っていません。今後機能が拡張されたときに使われる予定です)
public class Walking { public DateTime time; public Vector3 position; public Vector3 forward; public Walking(DateTime time, Vector3 position, Vector3 forward) { this.time = time; this.position = position; this.forward = forward; } }
Aボタンを押したときに、データをファイルに保存するようにしました。
コントローラのマッピングは、下記を参考にしています。
Map Controllers | Oculus Developers
using System; using System.Collections; using System.Collections.Generic; using UnityEngine; public class WalkingHistory : MonoBehaviour { [SerializeField] private GameObject player; [SerializeField] private GameObject LogObj; private Log Log; private List<Walking> walkings = new List<Walking>(); // Start is called before the first frame update void Start() { Log = LogObj.GetComponent<Log>(); // ログの記録 StartCoroutine(nameof(AddWalkingHistory)); } void Update() { // Aボタンが押されたら、ログを保存する if (OVRInput.Get(OVRInput.Button.One)) { // ファイル名は、適当にsampleuser_20211210080000.csvみたいな感じにしてみた var fileName = "sampleuser_" + DateTime.Now.ToString("yyyyMMddHHmmss") + ".csv"; Save(fileName, walkings); } } private void Save(string fileName, List<Walking> history) { // 後ほど作成。ファイル名と文字列のリストを渡してファイルを保存する。 Log.Output(fileName, WalkingListToCSV(history)); }
AddWalkingHistory関数を使って、ログをリストに追加していきます。
2秒に1回ログを追加するために、コルーチンを使っています。
private IEnumerator AddWalkingHistory() { WaitForSeconds cachedWait = new WaitForSeconds(2f); while (true) { walkings.Add(new Walking( DateTime.Now, player.transform.position, player.transform.Find("OVRCameraRig/TrackingSpace/CenterEyeAnchor").transform.forward )); // 2秒待つ yield return cachedWait; } }
WalkingのリストをCSVのリストに変換する関数はこんな感じです。
position.ToString()みたいな感じにしようかと思っていたんですが、その場合
(position.x, position.y, position.z)という形で出力されるので、カッコの扱いに悩んで却下しました。
private List<string> WalkingListToCSV(List<Walking> history) { List<string> str = new List<string>() {"time,position.x,position.y,position.z,forward.x,forward.y,forward.z"}; for (int i = 0; i < history.Count; i++) { str.Add(string.Join(",", new List<string>(){ history[i].time.ToString(), history[i].position.x.ToString(), history[i].position.y.ToString(), history[i].position.z.ToString(), history[i].forward.x.ToString(), history[i].forward.y.ToString(), history[i].forward.z.ToString() })); } return str; } }
ファイルの保存
実際にファイルを保存する、Logクラスです。
はじめに、CreateDirectory関数を使って、Logディレクトリがなかった場合は作成するようにしています。
using System.Collections.Generic; using UnityEngine; using System.IO; public class Log : MonoBehaviour { private static string filePath = string.Empty; void Start() { CreateDirectory(); } // ログ保存用のディレクトリを作成 private void CreateDirectory() { filePath = Application.persistentDataPath + "/Log/"; if (!Directory.Exists(filePath)) { Directory.CreateDirectory(filePath); } } // ログファイルの保存 public static void Output(string fileName, List<string> logs) { var FullPath = Path.Combine(filePath, fileName); File.WriteAllLines(FullPath, logs); } }
WalkingHisotry.csは、OVRPlayerControllerにアタッチして、Log.csはLogにアタッチしています。
Planeは床で、Cylinderは立っている三つの円柱のことです。
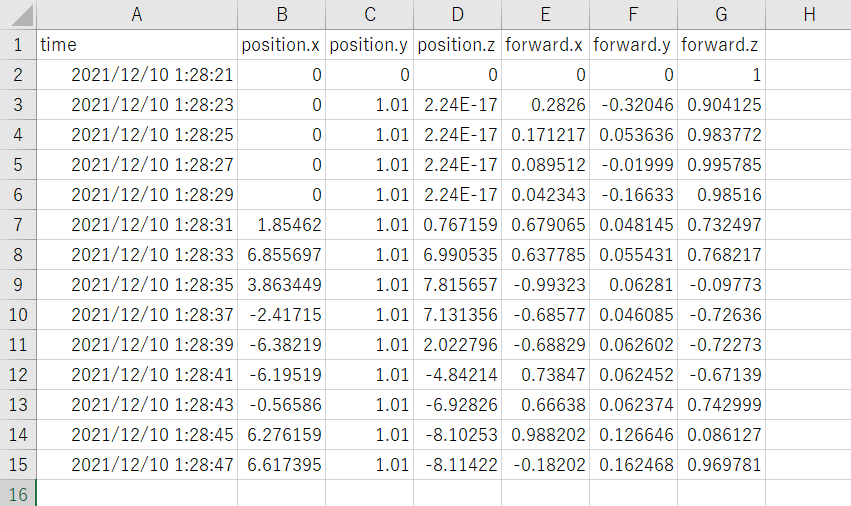
取得したログ
ログはこんな感じで取れました。
生成したCSVファイルのデータを利用する
先ほどのシーンを複製し、取得したデータを利用するシーンを作成しました。
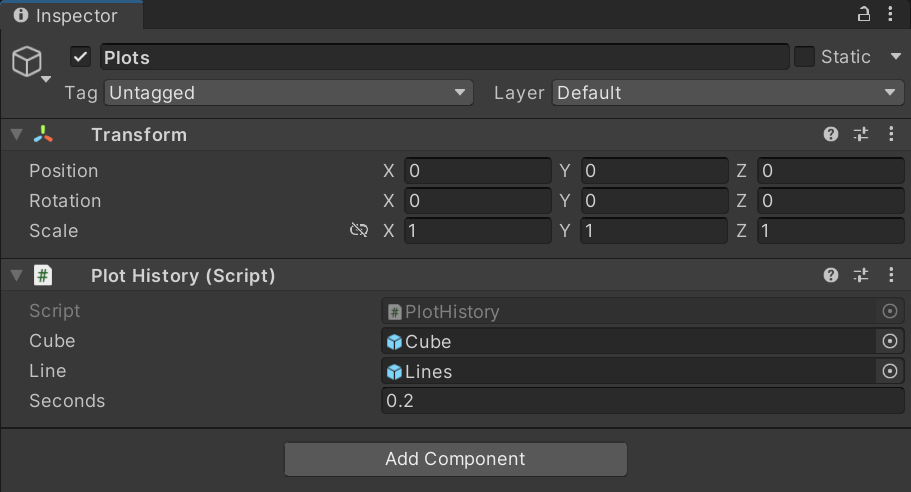
LoadとPlotsという空のGameObjectを作成し、それぞれにこれから作成するLoad.cs、PlotHistory.csをアタッチします。
また、軌跡を見る際はVRを使わないので、OVRPlayerControllerは削除し、TopCameraという、真上からのカメラを用意しました。
CSVファイルの読み込み
Load関数を作成しました。
ファイル名を良い感じに過去のデータ一覧から選択できるようにする手間を惜しんだので、
ファイル名は固定で、data.csvのファイルのみ読み込むコードになっています。
File.ReadAllLinesでCSVファイルをすべて読み込むと、1行ずつ文字列の配列dataに格納されます。
1行を、さらに ' , ' で区切ることで、time、position、forwardを取得することができます。
Convert.ToSingleは、文字列をfloatに変換するために使用しています。
using System.Collections.Generic; using UnityEngine; using System; using System.IO; public class Load : MonoBehaviour { private List<Walking> walkings; void Start() { walkings = new List<Walking>(); var filePath = Application.persistentDataPath + "/Log/data.csv"; Read(filePath); } public void Read(string filePath) { if (File.Exists(filePath)) { string[] data = File.ReadAllLines(filePath); for (int i = 1; i < data.Length; i++) { string[] d = data[i].Split(','); walkings.Add(new Walking( DateTime.Parse(d[0]), new Vector3(Convert.ToSingle(d[1]), Convert.ToSingle(d[2]), Convert.ToSingle(d[3])), new Vector3(Convert.ToSingle(d[4]), Convert.ToSingle(d[5]), Convert.ToSingle(d[6])) )); } } } }
立っていた場所にキューブを置いてみる
キューブを生成する関数、Plotを作成しました。
Inspectorで、キューブのオブジェクトと、何秒(seconds)に1個キューブを置くかを指定します。
CubeObj.transform.parent = transform; とすることで、Plotsの子オブジェクトとして、Cubeが生成されます。
public class PlotHistory : MonoBehaviour { [SerializeField] private GameObject Cube; [SerializeField] private float seconds = 2.0f; // 2秒に1回生成する public IEnumerator Plot(List<Walking> walkings) { WaitForSeconds cachedWait = new WaitForSeconds(seconds); GameObject CubeObj; for (int i = 0; i < walkings.Count; i++) { CubeObj = Instantiate(Cube, walkings[i].position, Quaternion.Euler(walkings[i].forward)); CubeObj.transform.parent = transform; // seconds 秒待つ yield return cachedWait; } }
この関数を、先程のLoad関数で、ファイルを読み込んだあと(if (File.Exists(filePath))の中の最後の行)で呼び出すようにします。
StartCoroutine(Plots.GetComponent<PlotHistory>().Plot(walkings));
これで、ログに記録した場所にキューブが生成されるようになりました。
線を引いてみる
最後に、キューブを置いた場所に線を引いてみます。
こちらの記事を参考にしました。
【Unity】今更ながらLineRendererで線を引く - 原カバンは鞄のお店ではありません。
RenderLine関数を作成しました。
[SerializeField]
private GameObject Line;
private void RenderLine(List<Walking> walkings)
{
GameObject beam = Instantiate(Line, walkings[0].position, Quaternion.Euler(walkings[0].forward));
LineRenderer line = beam.GetComponent<LineRenderer>();
// 頂点数
line.positionCount = walkings.Count;
// 線を引く
for (int i = 0; i < walkings.Count; i++)
{
line.SetPosition(i, walkings[i].position);
}
}
このとき、Inspectorはこんな感じです。
早めの、0.2秒に1個のキューブを生成するようにしています。
この関数を、Plot関数の最後に呼び出してやると、下のGIFのようになります。
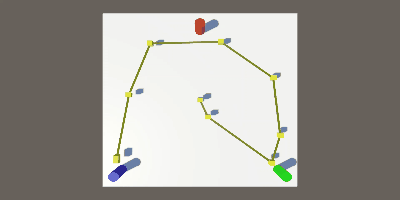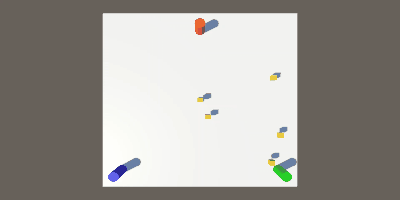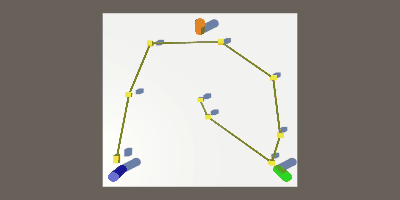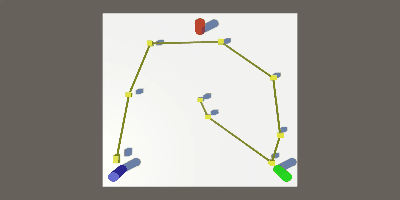
おわりに
キューブとキューブの間隔が広かったら、急いで移動したんだなとか、
間隔が狭かったら、ゆっくりor立ち止まっていたんだなとか、
そういったことが見られて結構面白いと思いました。
本当は、複数の移動パターンを用意して、ログ同士の比較をして、「何%くらい同じような動きをした」とか出したかったんですが、今回はそこまでは行っていません。
今後、それは別件でやる予定があるので、気が向いたら続きとしてブログに記述したいですね。
(こういうと、結局何も書かずに数ヶ月たったりすることが多いですが、3ヶ月以内くらいに続きを書けたらいいなと思っています)
sqlxでSUMを使う方法が分からなかった(わかった)
はじめに結論
SUMなどの集計関数を使うなら、モデルのタグに、`db:"SUM(hoge)"`とSUMも書きましょう
何故動かないのかわからなかった
例えば、次のようなデータのテーブル(sampleUser)があるとして、
| name | score |
| A | 10 |
| B | 20 |
| B | 30 |
次の形のデータが欲しかったんですね。
| name | score |
| A | 10 |
| B | 50 |
SQLを叩くとこうなるわけですが、このクエリをsqlxで実行することに躓いてしまいました。
SELECT name, SUM(score) FROM sampleUser GROUP BY name;
// 実行しようとしたもの nameScore := []SampleUser{} // 結果を格納する構造体のスライス err := sqlx.SelectContext( ctx, r.db, &nameScore, ` SELECT name, SUM(score) FROM sampleUser GROUP BY name `, ) // "missing destination name SUM(score) in *[]SampleUser"と怒られる(とても親切なメッセージ)
結論を言うと、モデルのタグが不適切でした。
type SampleUser struct { Name string `db:"name"` Score uint32 `db:"score"` }
このような形で、nameとscoreを定義していたのですが、`db:"score"`と定義してしまっていました。
返ってくる値はscoreではなく、SUM(score)なので、`db:"SUM(score)"`とする必要がありました。
(この記事の最初から二つ目の表は間違っている)
mysql > SELECT name, SUM(score) FROM sampleUser GROUP BY name; +------+------------+ | name | SUM(score) | +------+------------+ | A | 10 | | B | 50 | +------+------------+
次のようにタグを変更することで、集計関数を含んだクエリを、sqlx.SelectContextで実行することができました。
type SampleUser struct { Name string `db:"name"` Score uint32 `db:"SUM(score)"` }
もちろん、タグを変更せず、AS句を使ってSQLの方を変更しても動きますね。
type SampleUser struct { Name string `db:"name"` Score uint32 `db:"score"` } nameScore := []SampleUser{} err := sqlx.SelectContext( ctx, r.db, &nameScore, ` SELECT name, SUM(score) AS score FROM sampleUser GROUP BY name `, )
ブクマ記事のタイトルを使ってワード・クラウドを作成する
はじめに
こんにちは!はやいもので、もう12月ですね!
これは、SLP KBITアドベントカレンダーの4日目の記事です。他の部員の記事は以下からご覧ください!
adventar.org
今回は、タイトルにもある通り、はてなブックマークで、自身がブクマしている記事のタイトルからキーワードを抽出し、ワード・クラウドの画像データを作成します。
ワード・クラウドから、自分はこういうキーワードに興味を持っているというものを見ることが出来れば、面白いなと思っています!
ワード・クラウドとは
ワード・クラウドとは、タグ・クラウドの応用形で、文章ベースのコンテンツを視覚化して魅力的な文字空間を構成する、情報可視化の手法の一つです*1。
ワード・クラウドを構成する語句のサイズは、出現頻度から決まります。

開発環境
- Windows10 Pro 20H2
- Docker 19.03.13
コンテナのイメージ
使用する主なライブラリ
- feedparser
- MeCab
- Matplotlib
- WordCloud
今回使用したプログラムは、GitHubで公開しています。
実行方法などは、READMEを参考にしてください。
github.com
私はDocker上でアプリケーションを動かしましたが、Python3を動かせる環境があれば、以下に記述するプログラムは動作すると思います。
コンテナを使わない方は、プログラムに記述してあるファイルパスを適宜変更するようにしてください。
tree
. ├── Dockerfile ├── images │ └── image-CNaan.png // ワードクラウド画像 ├── requirements.txt ├── src │ ├── bookmark.py │ └── main.py └── userdic └── myDic.csv
ブクマ記事のタイトルを取得する
ブクマ記事のタイトルを取得するために、RSSを利用します。
RSSの詳しい仕様はこちらを参照してください。↓
はてなブックマークフィード仕様 - Hatena Developer Center
RSSは、https://b.hatena.ne.jp/${ユーザ名}/bookmark.rssから確認できます。
私のユーザ名はCNaanですので、次の通りです。
https://b.hatena.ne.jp/CNaan/bookmark.rss
上記のRSSからタイトルを取得するために、Pythonのライブラリであるfeedparserを使います。
Pythonでプログラム(bookmark.py)を作成しました。
import feedparser import re import sys from typing import List class Bookmark: hatena_id = "" def __init__(self, hatena_id: str) : self.hatena_id = hatena_id # 公開しているブックマークの数を求める def count_bookmark(self) -> int: d = feedparser.parse('https://b.hatena.ne.jp/{}/rss'.format(self.hatena_id)) content = d['feed']['subtitle'] # 'Userのはてなブックマーク (num)' match = re.search(r"(はてなブックマーク \()(.*?)\)", content) num = match.group(2).replace(',', '') # 公開しているブックマーク数 if not num.isdecimal(): print('Error: num is string', file=sys.stderr) return 0 return int(num) def get_title(self) -> List[str]: # 1ページに20件のデータがある。ページ数を求める bookmark_num = self.count_bookmark() max_page = (bookmark_num//20) + int((bookmark_num%20) > 0) titles = [] for i in range(max_page): d = feedparser.parse('https://b.hatena.ne.jp/{}/rss?page={}'.format(self.hatena_id, i+1)) entries = d['entries'] for entry in entries: titles.append(entry['title']) return titles bookmark = Bookmark("CNaan") titles = bookmark.get_title() print(titles)
インスタンス生成時に、はてなIDの"CNaan"を引数に入れ、初期化しました。
関数count_bookmarkでは、公開しているブックマークの数を求めています。(軽くRSSを見て、取得方法がわからなかったので、正規表現で文字列から取得しました。)
正規表現で取得しましたが、' , '区切りの数となるので、注意が必要です(コンマを取り除かないと、1000を超える人のブックマーク数が取得できません)。
関数get_titleは、タイトルを取得し、リストを作成します。
実行すると、タイトルの一覧のリストが出力されると思います。
ワード・クラウドの作成
日本語フォントの用意
日本語を出力するためには日本語フォントが必要です。
今回は、予めホストで持っているフォントファイルをコンテナ内にCOPYすることで対応しました。
今回はGoogle Noto Fontsを利用しました。
How to install fonts – Google Noto Fonts
ダウンロードし、.fontsというディレクトリの中にNotoSansCJKjp-Regular.otfを用意しました。
プログラム
from bookmark import Bookmark import MeCab import os from wordcloud import WordCloud #ワードクラウドの作成 def create_wordcloud(titles: str): fontpath = '/work/.fonts/NotoSansCJKjp-Regular.otf' tagger = MeCab.Tagger( '-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd' ) tagger.parse('') word_list = [] for title in titles: node = tagger.parseToNode(title) while node: word_type = node.feature.split(',')[0] word_surf = node.surface.split(',')[0] if word_type == '名詞': if len(set(["副詞可能", "数", "非自立", "代名詞", "接尾"]) \ & set(node.feature.split(",")[1:4])) == 0: word_list.append(node.surface) node = node.next word_chain = ' '.join(word_list) wordcloud = WordCloud(background_color=None, mode="RGBA", font_path=fontpath, width=900, height=500, relative_scaling=0.5 # フォントサイズの相対的な単語頻度の重要性 ).generate(word_chain) #ファイルの作成 wordcloud.to_file("/work/images/image-" + os.environ['HATENAID'] + ".png") def main(): hatena_id = os.environ['HATENAID'] bookmark = Bookmark(hatena_id) titles = bookmark.get_title() create_wordcloud(titles) if __name__ == "__main__": main()
システム辞書として、mecab-ipadic-neologdを使用しました。
GitHub - neologd/mecab-ipadic-neologd: Neologism dictionary based on the language resources on the Web for mecab-ipadic
mecab-ipadic-NEologdは、新語や固有表現に強い辞書です。週に2回以上更新されています(すごい)。
このプログラムでは、キーワードとして名詞を抽出するようにしています。なお、名詞の中の("副詞可能", "数", "非自立", "代名詞", "接尾")については除外するようにしています。
WordCloudのパラメータの、background_color=Noneと、mode="RGBA"を組み合わせることで、透過画像となります。また、relative_scalingの値(0から1)によって、文字の出現頻度に対する文字サイズの比率を設定することができます。
その他のWordCloudのパラメータについては以下を参照ください。
wordcloud.WordCloud — wordcloud 1.8.1 documentation
出力してみる
画像を作成してみると、次のような感じになりました。
Qiitaが大きいですね。
今回は、自分の趣向が見たいなーと思っているので、Qiitaの記事のタイトルは必要ですが、サービス名である、"Qiita"という単語自体は、今回はそこまで重要ではありません。よって、ここからQiitaを除外したいと思います。
また、noteやSpeaker Deckも除外します。

stop wordsの追加
除外する単語を格納したリスト、stop_wordsを作成します。
from bookmark import Bookmark import MeCab import os from wordcloud import WordCloud #ワードクラウドの作成 def create_wordcloud(titles: str): fontpath = '/work/.fonts/NotoSansCJKjp-Regular.otf' stop_words = ['Qiita', 'note', 'Speaker Deck'] tagger = MeCab.Tagger( '-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd' ) tagger.parse('') word_list = [] for title in titles: node = tagger.parseToNode(title) while node: word_type = node.feature.split(',')[0] word_surf = node.surface.split(',')[0] if word_type == '名詞': if (node.surface not in stop_words) and \ len(set(["副詞可能", "数", "非自立", "代名詞", "接尾"]) \ & set(node.feature.split(",")[1:4])) == 0: word_list.append(node.surface) node = node.next word_chain = ' '.join(word_list) wordcloud = WordCloud(background_color=None, mode="RGBA", font_path=fontpath, width=900, height=500, relative_scaling=0.5 # フォントサイズの相対的な単語頻度の重要性 ).generate(word_chain) #ファイルの作成 wordcloud.to_file("/work/images/image-" + os.environ['HATENAID'] + ".png")

ユーザ辞書の作成
ストップワードとしてSpeaker Deckを記述したにも関わらず、画像にはSpeaker Deckが表示されていることがわかります。これは、下のように、Speaker と Deck が別の単語として認識されているためです。
Speaker 名詞,固有名詞,組織,*,*,*,* Deck 名詞,一般,*,*,*,*,*
また、Speaker と Deckは、辞書に登録されていない単語で、MeCabが品詞を推定しています。
Speaker Deckを、一つの単語として認識させるために、ユーザ辞書を作成します。CSVファイル(userdic/myDic.csv)を作成しました。
ユーザ辞書の追加は、こちらを参考にしました。
blog.apar.jp
このとき、下の例のように、システムの品詞体系に沿わない辞書登録を行うと、エラーとなります。
Speaker Deck,,,1,名詞,固有名詞,*,*,*,*,Speaker Deck,,,
$ /usr/lib/mecab/mecab-dict-index -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd -u /work/userdic/myDic.dic -f utf-8 -t utf-8 /work/userdic/myDic.csv reading /work/userdic/myDic.csv ... context_id.cpp(96) [it != left_.end()] cannot find LEFT-ID for 名詞,固有名詞,*,*,*,*,*
固有名詞を、さらに分ける必要があります。
MeCabユーザ辞書作成時の陥りがち?なミス(エラー: cannot find LEFT-ID) - Qiita
Speaker Deck,,,1,名詞,固有名詞,組織,*,*,*,Speaker Deck,,,
"組織" を追加してみると、以下のように成功します。
$ /usr/lib/mecab/mecab-dict-index -d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd -u /work/userdic/myDic.dic -f utf-8 -t utf-8 /work/userdic/myDic.csv reading /work/userdic/myDic.csv ... 1 emitting double-array: 100% |###########################################| done!
また、mecabrcに作成したユーザ辞書の情報( userdic = /work/userdic/myDic.dic )を追加します。
echo userdic = /work/userdic/myDic.dic >> /usr/local/etc/mecabrc
出力結果を確認すると、ユーザ辞書が適用されていることがわかります。
>>> import MeCab >>> tagger = MeCab.Tagger() >>> print(tagger.parse('Speaker Deck')) Speaker Deck 名詞,固有名詞,組織,*,*,*,Speaker Deck,,,
結果
docker runをする際、環境変数ではてなIDを設定し、また、画像出力用のディレクトリをコンテナ内のディレクトリとマウントします。
$ docker build -t myword-cloud:1.0 . $ docker run -it --rm --name myword-cloud -e HATENAID=CNaan -v $(pwd)/images:/work/images myword-cloud:1.0


はてなサマーインターン2020に自宅から参加しました!!
はじめに
はてなサマーインターン2020に参加しました。
タイトルの通り、オンラインだったので家インターンです。
オンラインインターンでは、PCなどの環境は自分で用意する必要がありました。
Ubuntu 20.04/CPU 3.60 GHz 8コア Intel Corei7 9700K/メモリ 32GBで参加しました。
参加まで
はてなインターンとの出会い
はてなのインターンの存在は、2年前の先輩(![]() id:guni1192)の参加報告で知りました!!
id:guni1192)の参加報告で知りました!!
guni1192.hatenablog.com
developer.hatenastaff.com
![]() id:guni1192は、大規模システム開発コースに参加していて、私がやっていることとは分野が違うのですが、当時からはてなはいいぞという布教を受けていました。
id:guni1192は、大規模システム開発コースに参加していて、私がやっていることとは分野が違うのですが、当時からはてなはいいぞという布教を受けていました。
そして、今年度自分は学部3年生で、![]() id:guni1192が参加した時と同じ年齢になり、今年は応募するぞーー!!と応募しました。
id:guni1192が参加した時と同じ年齢になり、今年は応募するぞーー!!と応募しました。
はてなという会社については、うごメモはてなから始まりはてなダイアリー、はてなブログ、はてなブックマークなど、いつもお世話になっています。
ちなみにブログははてな記法で書く派です。
選考
課題は、dockerコマンドを実行し、表示される問題に回答する、というものでした。
$ docker run --rm -it hatena/apply-for-internship-2020:latest
https://github.com/hatena/apply-for-internship-2020
質問に回答すると、トークンが発行され、そのトークンを応募フォームにペーストすれば、課題達成です!
この後の面接で、![]() id:cockscomb さんとお話したのですが、この課題にはやさしさが詰め込まれていました。面接はGoogle Meetを使ってオンラインでしました。
id:cockscomb さんとお話したのですが、この課題にはやさしさが詰め込まれていました。面接はGoogle Meetを使ってオンラインでしました。
選考について、詳しくはこちら↓
hatenacorp.jp
事前課題
事前課題は、hatena/Hatena-Intern-2020-Templateのテンプレートリポジトリを基にして、プライベートリポジトリの作成、およびREADMEを参考に環境構築を行うというものでした。
環境構築にとても時間がかかるということはなく、負担はなかったです。
事前交流会
インターン生と、はてなの方で、事前交流会を行いました。
Zoomで![]() id:onishiさんから歓迎の言葉を頂いたり、三つのグループに分かれてテーマに沿った話をしました。
id:onishiさんから歓迎の言葉を頂いたり、三つのグループに分かれてテーマに沿った話をしました。
社員の方や他のインターン生と気楽に話すことができ、とても楽しかったです!!
飲み物については、お酒を家で一人で飲む習慣がなく、水を飲んでました。酒を準備している方もいて、酒を飲んでも良かったかなと思いました。社員の方は大体の方が酒を用意していた印象があります(違ったらすみません)。
ちなみに水はすごくおいしいので好きです。
最後には、![]() id:motemenさんから激励の言葉を頂きました。
id:motemenさんから激励の言葉を頂きました。
はてなサマーインターン2020開始!!
コミュニケーションについて
はじめに、インターン期間中のコミュニケーションについて説明しておきます。
メインで使用したツールはDiscordとScrapboxです。講義や交流会ではZoomを使いました。
事前課題やインターン参加中に質問などあればDiscordのチャットで質問をしました。業務連絡や雑談など、連絡はDiscordで行っていました(重要な連絡など一部の連絡は一部メールで)。
ちなみに事前交流会でポケモンGoが好きだという話をしたら、Discordにpokemongoチャンネルができてました。
初日の講義はZoomを用いて行い、二日目以降はDiscordのボイスチャンネルにミュートでイン、会話する時にミュート解除という感じでした。
マイクは、bluetoothイヤホンを使っていたのですが、充電の残量が時々気になりました。結果としては、ミュート中や休憩中に充電をしていたので、充電が切れることはなかったです。
また、常にカメラオンではないという状態は、とても楽でした。
課題に取り組む際は、メンター一人とメンティー二人のグループに分かれて活動するのですが、私のグループでは、質問やミーティングの際は、カメラをオンにしていました。
また、Discordと併用してScrapbox(https://scrapbox.io/)に定期的に手動で作業ログを吐くことで交流しました。
この記事も、Scrapboxのログを参考に書きました。記録残しておいてよかった……!!

1日目
講義
初日は講義デーでした。
講義動画は、後々公開されるらしいです。
hatenacorp.jp
↑ こちらのページや、Twitterの@hatenatech、「Hatena Developer Blog」で新着情報を待ちましょう。
45分の講義が講義1から講義5までありました。
- Web API
- コンテナ
- Kubernetes
- マイクロサービス
- 課題説明
どの回もとても面白い内容でした。
コンテナの回では、Docker Quizがあり、とても面白かったです。
Q6までは解答できたのですが、Q7は解答できませんでした。
後でじっくり解説を見返したいと思います。
Kubernetesの回では、オートスケールの設定などを行いました。
Apache Benchを使って負荷テストを行いました。
$ kubectl autoscale deployment blog --cpu-percent=50 --min=1 --max=10
目標となるPod全体の平均CPU使用率を50%、オートスケールする際のPod数の下限を1、上限を10としていました。
以下の画像のように、大量にリクエストを投げたところ、Pod数の増加を確認できました。
Podが増えたとき、「増えたーー!!」となりましたね。嬉しい😆

残念ながら、スケールインの様子は確認できませんでした。
もっとたくさんリクエストを投げて、Podを増やしてみるべきだったかなと思っています。
課題
課題説明では、課題内容に加え、テストを書くこと、コミットの粒度を意識することの説明を受けました。
課題は、
- ブログ記事に記法を実装すること
- タイトルの自動取得サービスを作成すること
加えて、発展課題がありました。
記法というのは、見出し記法やリンク記法、リスト記法といったもののことです。
タイトルの自動取得サービスについては、ブログに以下のような記法で入力されたとき、
[](https://hatenablog.com) # リンク記法で、[]内のタイトルが省略されている
https://hatenablog.comのページからタイトルを取得し、
[はてなブログ](https://hatenablog.com)となるようにするというものです。
課題開始
講義が終わって17時くらいからは、メンターが一人、メンティーが二人のグループで活動しました。
2日目から4日目は、主にこのグループで活動することになります。
メンターは ![]() id:yigarashi さんでした。
id:yigarashi さんでした。
![]() id:cordx56 さんと一緒にyigarashi部屋での活動を始めました。
id:cordx56 さんと一緒にyigarashi部屋での活動を始めました。
![]() id:cordx56さんはTweet generatorでバズった人です。インターン3日目くらいに知りました。すごい。
id:cordx56さんはTweet generatorでバズった人です。インターン3日目くらいに知りました。すごい。
歓迎会
夜は歓迎会で、自己紹介をしたりわいわい夕飯を食べました。
![]() id:namachan10777にカレー屋の紹介をされました。今度食べに行こうと思います。
id:namachan10777にカレー屋の紹介をされました。今度食べに行こうと思います。
2日目
この日は、見出し記法、リンク記法、リスト記法の実装を行いました。
Go言語を使って実装しました。推奨されていた、goldmarkというMarkdownライブラリを使用しました。何らかのMarkdownライブラリを利用している人がほとんどでしたが、![]() id:cha-shu00さんはパーサモジュールを自作していました。すごい……。記事の最後に他のインターン生の記事を載せているので、気になる方は
id:cha-shu00さんはパーサモジュールを自作していました。すごい……。記事の最後に他のインターン生の記事を載せているので、気になる方は![]() id:cha-shu00さんの記事を読みましょう。
id:cha-shu00さんの記事を読みましょう。
ちなみにこの日、見出し記法で'##'>'###'>'#'の順にフォントサイズが大きいという問題にぶつかりました。

原因っぽいものは調べると出てきたのですが、h1タグの仕様っぽいです。
h1タグ、articleやsectionでネストされるとフォントサイズが小さくなるらしいです。知らなかった……。
この時、articleやsectionで結構ネストされていたので、h1がh5くらいのサイズになっていたのかなと思いました。
https://stackoverflow.com/questions/6851833/h1-is-smaller-than-h2-in-firefox-and-chrome
3日目
2日目で記法を実装したのですが、これに加えて、独自記法というものを実装していきます。
この日の午前中は、独自記法の途中に改行を入れるとInternal Server Errorとなる問題に取り組んでいました。![]() id:yigarashiさんに手伝っていただきました。比較的直ぐに、Go言語のプログラムで、範囲外参照をしていることがわかりました。
id:yigarashiさんに手伝っていただきました。比較的直ぐに、Go言語のプログラムで、範囲外参照をしていることがわかりました。
goldmarkのモジュールの拡張方法など、理解するのに時間がかかってしまっていたので、その辺りを理解する力を、もっとつけていきたいなあと思いました。
ランチタイム
ランチ時間(13:00 ~ 14:00)は、Discordのランチルームでわいわいして良いという雰囲気でした。
この日は、![]() id:chris4403さんや
id:chris4403さんや![]() id:onishiさんがいらっしゃり、楽しく雑談をしながら食事をしました。
id:onishiさんがいらっしゃり、楽しく雑談をしながら食事をしました。
例えば、好きな映画の話をしました。
「魔女の宅急便」のどんなシーンが好き?といった話をしました。ちなみに![]() id:cordx56さんは魔女の宅急便が好きです。
id:cordx56さんは魔女の宅急便が好きです。
私は、昔見たとき、「キキが飛べなくなった」ことが悲しかったという話をしました。昔はデッキブラシの見た目がかっこよくないと思っていたんですね。
社員の方は、「お父さんがキキを見送るシーンが感動する」と言ってました😢
4日目
この日は、タイトルの自動取得をできるようにしました。
Markdown記法をHTMLに変換する作業は、renderer-goというサービスが行うのですが、URLからタイトルを取得するのは、fetcherサービスという別のサービスが行います。今回の課題では、fetcherサービスを作るところから行いました。
タイトルの自動取得は、ASTの各ノードをvisitし、タイトルが未指定の場所に、fetcherサービスで取得したタイトルを差し込むという方法で行いました。
ここで、タイトルを差し込む部分について、どのようにすればテストを書きやすい設計になるかわからず、![]() id:yigarashiさんにテストの書きやすい設計について教わりました……。理解に時間がかかり、自分はテストやプログラムを書きなれていないと感じました。今後の目標は、テストを書き慣れることです。
id:yigarashiさんにテストの書きやすい設計について教わりました……。理解に時間がかかり、自分はテストやプログラムを書きなれていないと感じました。今後の目標は、テストを書き慣れることです。
また、5日目には成果発表を行うので、その資料作りをしました。

5日目
成果発表会
一人5分以内で、課題について取り組んだ内容をプレゼンテーションする、というものでした。
PCのフロントカメラが前々から調子の悪い時があったのですが、当日再起動しても途中で切れそうだったので、画面共有用のPCと、カメラ用のiPadの2台からZoomにログインさせていただきました。
私は、基本課題である、記法(見出し記法、リンク記法、リスト記法)の実装、独自記法の追加、タイトルの自動取得に取り組んだので、それを発表しました。
Scrapboxで、成果発表会会場が用意されていたので、そちらに発表へのコメントを書き込んだり、はてなスターのように、良かった!!と他の人の発表に自分のアイコン画像を沢山ぺたぺたしました。いっぱいつけるの楽しいですね、もっといっぱいつければよかった(´・ω・`)
ところで、3日目に独自記法を追加したと言ったのですが、どのような記法かは述べていませんでした。
私は、独自記法として、以下略記法を追加しました。
以下略記法は、(ryを使った記法です。
(ry(かっこあーるわい)の説明は、こちらを参考にしてください→(ryとは ウェブの人気・最新記事を集めました - はてな
恐らく、昔うごくメモ帳をやったり、ブログを書いたりしていた人は、言葉の末尾に(ryを付ける文化をご存じなのでは?と思っています。私は(ryを多用してました。

以下略記法は、detailsタグとsummaryタグを使った表記となっています。次の1文は、detailsタグを使っています。
表示されているよ
省略されているよ
以下略記法について、面白いと言っていただけたので嬉しいです!

そういえば発表の時にあまり説明をしなかったなと思ったのですが、「(ryと省略してるけど、実は続きを書いている」という優しさを詰め込んだ表現です。
発表会終わり
発表会が終わった後は、アンケートを書いたり、面談したり、このブログを書いたり、19時から表彰式&送別会に出席したりしました。
面談では、PCのフロントカメラの調子が悪いからとiPadから参加したら、Google Meetに「他のアプリを開いているとカメラ使えません」と言う感じに怒られました。最後の最後に自分の顔を見せられなくて悲しくなりましたね……。
送別会では、初日の歓迎会同様、わいわい楽しんで話すことができました。
ところで無人島って、誰でも上陸できるんですね……。
ちなみに、この日も酒を買い忘れたので水を飲みました。水は美味しい。
主食はどん兵衛きつねうどんです。四国なので多分西です。
5日間を振り返って
はてなの人、褒めるのが上手いなと思いました。
参加前の面接では、![]() id:okikukun さん及び
id:okikukun さん及び ![]() id:cockscomb さんとお話したのですが、
id:cockscomb さんとお話したのですが、
なんでも肯定から入ってくださるという印象があり、素敵な方々だなと思いました……!!
インターンの選考をされるという経験が初めてで、「一体どんな角度から攻めてくるんだ……!?」と若干ドキドキしていたのですが、
面接では、![]() id:okikukunさんと
id:okikukunさんと![]() id:cockscombさんの暖かさに包まれました……。
id:cockscombさんの暖かさに包まれました……。
インターンに参加前からとても親切だったので、なんと素敵なんだ……😇と感動しました。
結果も早く伝えていただいたので、結果をドキドキ待つ時間が少なくて心臓にやさしかったですね。
インターン参加中も、メンターの![]() id:yigarashiさんに、「惜しいところまで行ってます!」というように、やる気を削がないアドバイスをたくさん頂いて、凄いなあと思いました……!!人と話すときは、はてなの方々の暖かさを真似していきたいと思いました。
id:yigarashiさんに、「惜しいところまで行ってます!」というように、やる気を削がないアドバイスをたくさん頂いて、凄いなあと思いました……!!人と話すときは、はてなの方々の暖かさを真似していきたいと思いました。
また、お気づきの方もいらっしゃるかと思いますが、はてなブログPROになってます。
インターン参加報酬にいただきました。やったーー!!
最近ブログをあまり書いていなかったので、モチベーションがあがりますね💪
長々と書きましたが、今回のインターンで感じたことを箇条書きすると、次のような感じです。
- はてなの方々は優しくて暖かい
- テストをしっかり書こう
- オンラインランチ会やその他交流会が楽しかった
落ち着いてきたら、オフィスランチを食べてみたいですね……。
他のインターン生の記事にもありましたが、これだけ学ばせていただいて3万円分のAmazonギフト券を頂けるの、すごい。
参加前は、「3万か~~へ~~」くらいに思っていたのですが、インターンが終わった今となっては、お金貰えるとかおかしいのでは????と感じてきました(そのくらい良いインターンでした)。
最後に、
はてなサマーインターン2020最高でした!!!!
他のインターン生の記事一覧
順次追加していきます。
cha-shu00.hatenablog.com
mizsk.hatenablog.com
blog.starry.blue
pyteyon.hatenablog.com
その他
眠気があまり無いので、さっさと一個ずつ終わらせないとなのですが、どこで陶芸するかって話なんですかね? #tweetgen https://t.co/Cyuf20FMqs
— 甘口 | cnaan😊 (@butterchickenC) August 28, 2020
![]() id:cordx56さんに広告費を貢いだ。
id:cordx56さんに広告費を貢いだ。

久々に家にあるぬいぐるみを出した。かわいい。